Notes on CoW mappings
Hello, hackers! I’m currently working on a cool project: Fast isolate cloning. In short, it’s a new V8 feature that quickly instantiates fresh isolates by cloning existing ones. While developing it, I explored and tested several strategies for maintaining and cleaning copy-on-write (CoW) memory mappings. I’d like to share the results of this subtask with you — both to save you time on similar problems in the future and, of course, for a bit of technical entertainment.
The cloning problem
First, let’s define the model. Imagine a single, contiguous block of memory - we will call it the pointer cage. Within this cage are N contiguous sub-intervals.
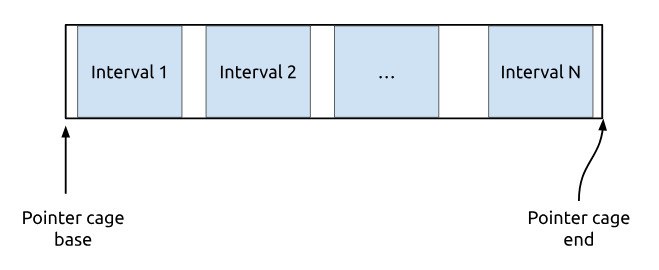
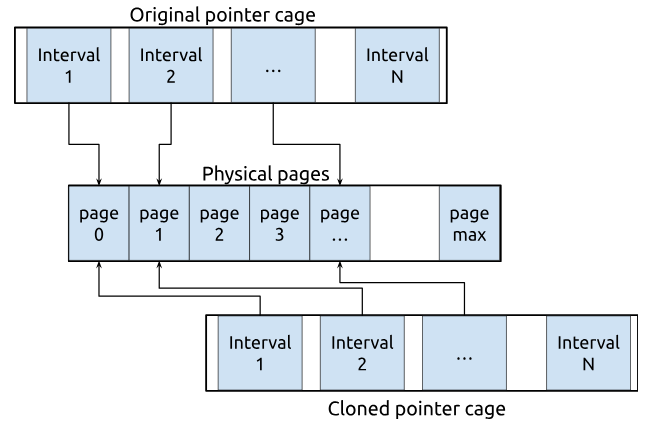
My goal is to create a CoW clone of a pointer cage, including all its sub-intervals. After cloning, I’ll have two pointer cages that share the same physical memory pages.
Next, I need to run N requests against the cloned pointer cage. Each request takes a fresh interval within the clone and modifies only a small fraction of its memory - about 20 % of that interval’s virtual pages, which matches what I see in practice. When the request finishes, the interval must be restored to its original, unmodified state.
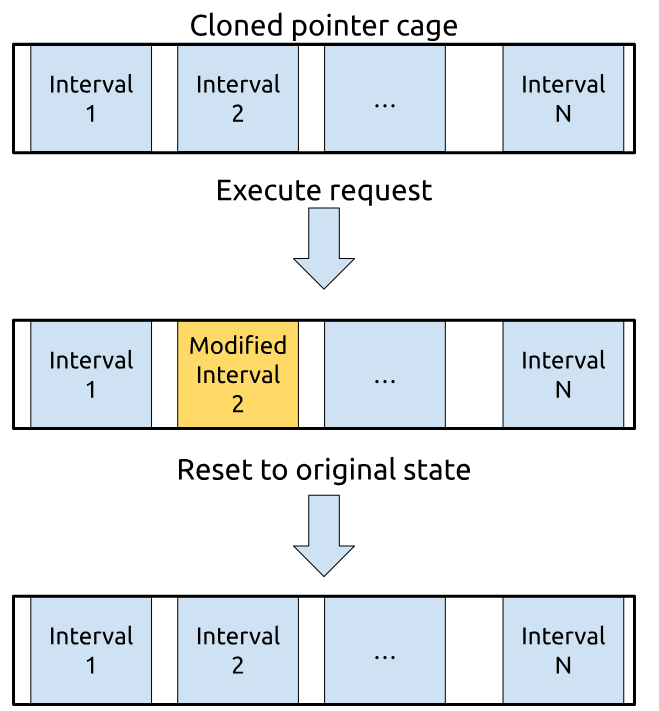
Think of the cloned pointer cage as a pool of intervals. Each request checks out an interval from the pool, modifies it, and then returns it when finished. In the demo code, it looks like this:
Pool pool(original_mapping_base_address);
// Client request code
auto interval = pool->GetInterval();
ModifyInterval(interval);
pool.FreeInterval(interval);
Now we can spell out the objective: build a system that runs N requests concurrently while keeping the total processing time as low as possible. Concretely, we need to implement the Pool class so that it handles all parallel requests in the shortest time.
We’ll lean on the OS’s copy-on-write support and let the kernel do most of the heavy lifting. Linux offers two main CoW paths: using fork, or using memory-backed files. Because we don’t need a separate process, fork isn’t a good fit. Instead, we create an anonymous, memory-backed file with memfd_create, map the original pointer cage into it, and later open a private, CoW view of that file via mmap with the MAP_PRIVATE flag:
int fd = memfd_create(...);
ftruncate(fd, size);
void* original_mapping_base_address = mmap(MAP_SHARED, fd);
FillOriginalPointerCage(original_mapping_base_address);
void* clone = mmap(MAP_PRIVATE, fd, 0);
This setup will be our baseline for the discussion — there aren’t many alternative ways to approach it. Still, there are several strategies for implementing GetInterval and FreeInterval, so let’s dive in.
Solution 1: full reset
The simplest approach is to make FreeInterval a no-op and let intervals remain “dirty” for a while. When no clean intervals are left, we reset the entire cloned pointer cage to its original state - assuming no clients are still using it.
Pool pool(original_mapping_base_address);
ExecuteClientsRequests(&pool, kNumberOfClients);
pool.FullReset();
GetInterval:
assert(!intervals_stack.empty());
auto interval = intervals_stack.top();
intervals_stack.pop();
return interval;
FreeInterval(interval): /*do nothing*/
To wipe all modifications from every interval in one shot, we can lean on the OS. When a client writes to a private page inside the cloned pointer cage, the kernel allocates a new physical page to protect the original and keeps track of both pages. We can then tell the kernel to discard those private copies and revert to the originals with madvise(..., MADV_DONTNEED). Despite the name, madvise here isn’t merely a suggestion - it’s an immediate command that frees the dirty pages from our cloned cage. (There’s a fun talk out there on how this counter-intuitive API name came about.)
FullReset():
madvise(cage_clone_base_, clone_size_, MADV_DONTNEED);
RefillIntervalStack();
This approach works well in aggregate: we skip the overhead of freeing individual intervals and release them all at once, so the amortized cost stays low. The catch is that madvise(..., MADV_DONTNEED) flushes the TLB; after a full pool reset, we pay the penalty of accessing uncached data. In addition, every time a client requests an interval the pool hands out a brand-new one, which further hurts cache locality. Ideally, each client would reuse the same interval more frequently.
Solution 2: tracking + madvise
This time, let’s track exactly which pages each request modifies. On Linux, you can do this by installing a signal handler and making the cloned pointer cage read-only. Whenever a write occurs, the kernel raises a signal; inside the handler, you switch the page to read-write with mprotect and log the page’s address.
This adds a small overhead - each write now incurs a signal and an extra mprotect - but the payoff is a much more precise FreeInterval. When an interval is released, you call madvise(..., MADV_DONTNEED) only on the pages that were actually changed, instead of flushing the entire cage.
GetInterval: /*the same*/
FreeInterval(interval):
for (auto dirty_page : dirt_pages(interval)) {
madvise(dirty_page.base(), kPageSize, MADV_DONTNEED);
}
intervals_stack.push(interval);
With this approach, intervals are returned to the pool already cleaned, which is a big win. The trade-off is a slightly longer request time: we have to scrub the modified pages and each write incurs an extra mprotect, adding overhead.
Solution 3: tracking + memcpy
To improve caching properties and reduce syscall pressure for madvice in FreeInterval we can just mem-copy original data for the original version of interval from the original pointer cage. Yes, it will use more physical memory but should provide a cache friendly solution.
GetInterval: /* same as in (2) strategy */
FreeInterval(interval):
for (auto dirty_page : dirt_pages(interval)) {
memcpy(dirty_page.base(), dirty_page.original_base(), kPageSize);
}
intervals_stack.push(interval);
Testing and results
To evaluate all three approaches, I spin up several threads. Each thread repeatedly checks out an interval, performs a request, and returns the interval to the pool. Every thread runs the same number of requests, and each request simply copies a set of virtual pages from one location in the interval to another. I record the total wall-clock time for all requests to compare the strategies. The benchmark code is available here. Feel free to pause now and test your systems-programming instincts: which strategy do you think will be the fastest?
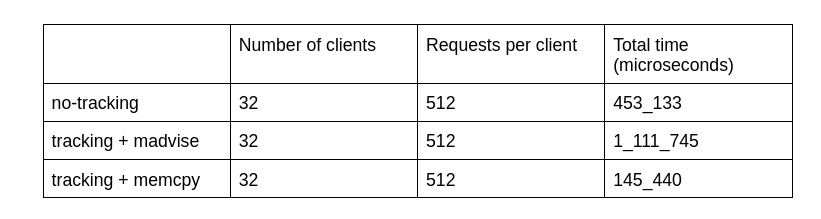
As the results show, the simplest approach - plain memcpy is the clear winner. Because the copy happens entirely in user space, it avoids costly kernel crossings and benefits from better cache locality. The trade-off is higher memory usage: duplicated pages remain allocated until you explicitly reclaim them. In real-world code, you’d combine the memcpy strategy with periodic page reclamation to keep the footprint in check.
So, now you know how to create a CoW mapping and how to fastly clean them to their original state. I hope you enjoyed the reading and had a good time.
P.S.
This work was sponsored and motivated by Cloudflare.