Optimization of Wasm’s indirect calls for SpiderMonkey
Hello hackers, part of last year and part of this year I was working on some cool optimization for Wasm call_indirect instruction in SpiderMonkey and recently it was finally landed. So, grab some food and let me share this story with you.
Links: SpiderMonkey, the bug
Introduction
As you already may know there is call_indirect instruction in Wasm which takes two immediates table_index and type_index, one function_index operand and calls a function indirectly through a given table and given function index. The function at tables[table_index][function_index] is checked against types[type_index] type and the call is aborted with a trap if it does not match.
Let’s see the usage of call_indirect for simple c++ code compiled to wasm via llvm:
class Base {
public:
virtual int foo() { return 1; }
};
class Derived : public Base {
public:
int foo() override { return 2; }
};
int Bar(Base* base) {
return base->foo();
}
Here we have Bar function that will be compiled into the following wat code:
Bar(Base*): # @Bar(Base*)
local.get 0 // push this
local.get 0 // push this again
i32.load 0 // load dispatch table and consume one this
i32.load 0 // load index of foo and consume dispatch table
call_indirect (i32) -> (i32) // call by index and consume this
end_function
We emit a simple virtual call because c++ compiler can’t inline or devirtualize this function and we are using call_indirect instruction because this is the only way in the current Wasm spec to implement indirect calls. Moreover, we have to use the same code when we are calling functions through pointers in C language.
You may think that you should avoid such indirection in your production wasm modules because of performance concerns and you are right! But, sometimes you have to use some existing C or C++ or Rust libraries which use indirection.
Also, you may ask how many functions are called through the call_indirect instruction in the wild Internet? So, Everything Old is New Again: Binary Security of WebAssembly, Table 2 tells us that on average 49.2% of all Wasm functions are called indirectly in the article's program corpus.
Conservative approach
Let’s dive in and see how call_indirect is implemented in SpiderMonkey. So, the following pseudocode describes the real binary code which SpiderMonkey JIT compilers generate for call_indirect instruction:
elem = table[index]
preserve_current_state()
test elem.code_ptr against null
switch_current_state(elem.instance)
call elem.code_ptr
restore_current_state()
Since tables in WebAssembly can be populated with imported functions from JS or imported functions from other wasm instances or it can be local functions from the current instance and since we call all these functions indirectly via runtime provided index we have to emit such conservative code.
Is it slow? Well, yes, for example asm.js did a better job for this. It is slow because preserving the current state and restoring it eats precious ticks of the processor. You may ask what is actually the state of running Wasm code? Each Wasm instance has its own pointers into its memories, tables and etc, these all together make the current state of running wasm code and when we need to call, for example, a function from a different wasm instance we have to emit a roundtrip switch for states.
Idea of optimization
Lets see more at our c++ example again, but this time let’s see the text of the whole wat module:
(module
(type $t0 (func (param i32)))
(type $t1 (func (param i32) (result i32)))
(table 1 1 funcref)
(elem (table 0) (i32.const 1) func $Bar ...)
(memory 2)
;; exports, imports, data sections, other functions definitions etc.
;; Bar function
(func $Bar (type $t0)
local.get 0
local.get 0
i32.load 0
i32.load 0
call_indirect $t1
end_function
)
)
The main observation here is that function Bar is actually a local function and we don’t need to be conservative and switch states. Moreover, by my subjective empirical observation almost all wasm applications today are single module applications. So, in many cases we can do less work because we are calling local functions. So, for our example above we can use a simplified version of code:
elem = table[index]
test elem.code_ptr against null
call elem.code_ptr
Much better, isn’t it? In general if the table isn’t exported or imported and we are calling a local function then we could use the simplified scheme. But how do we know at runtime that we are going to call a local function or an external one? We can’t just insert ifs and spoil our straightforward code for the local case.
Uniform representation for call_indirect and decorators
To achieve the desired code we can’t emit more assembly instructions at the call site and so, the only way to do this is to modify the functions that we are calling. Here decorators come. So, instead of calling function Bar we will call a new function Decorator(Bar) that will change the state on callee behalf and call the original function.
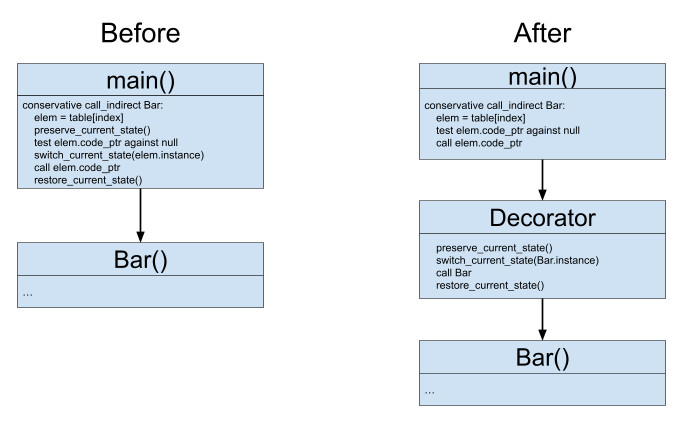
The remaining piece of puzzle is when we should decorate our functions? Well, there is only one perfect time to do this - when we are initializing tables. More precisely, when we are populating a table with given functions we know all the information. We know what is the source of the function and whether it is imported or not and so, we can create these decorators at instantiate time and then replace table entries from pointers to functions to pointers to decorators.
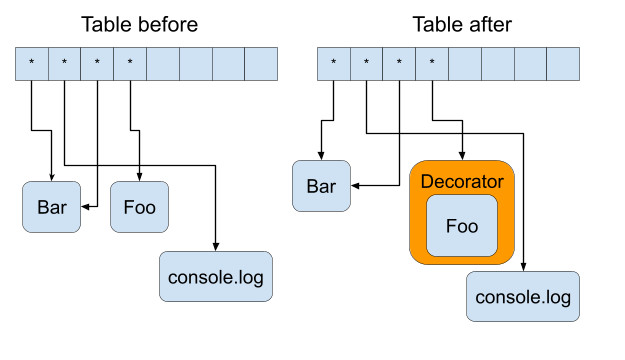
In the current scheme we actually introduced one interstitial jump to the decorator and so we made call_indirect actually slower than it was before. But, thankfully to our observation in the previous paragraph we can replace pointer to decorator with pointer to raw function’s code if we know that this function is local and the table is private. You can see in the picture above that Bar isn’t decorated because it is local. Our scheme for local case will look like this:
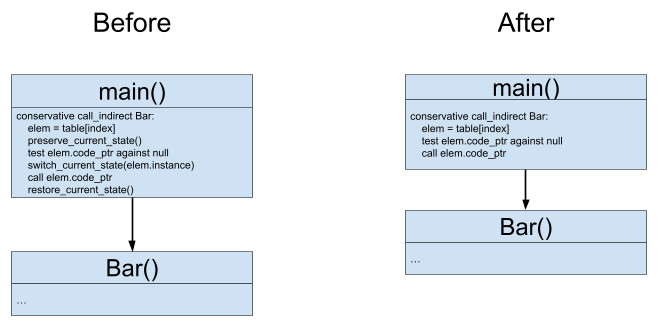
And this is actually what we want - for local functions we don’t need to pay for any switching. Of course, this approach will slow down the cross-instance calls but, as I said previously, call_indirect of local functions are a really frequent case for current wasm state.
Results
Let’s do some measurements, but first let me introduce you with the micro benchmarks. We are going to measure the total amount of time that call_indirect will take for a local target and for an external one. Target functions are intentionally made simple not to introduce unnecessary delays. The benchmark can be found here. JFYI, the results have been obtained via not very modern core i7 laptop with 16Gb of RAM.
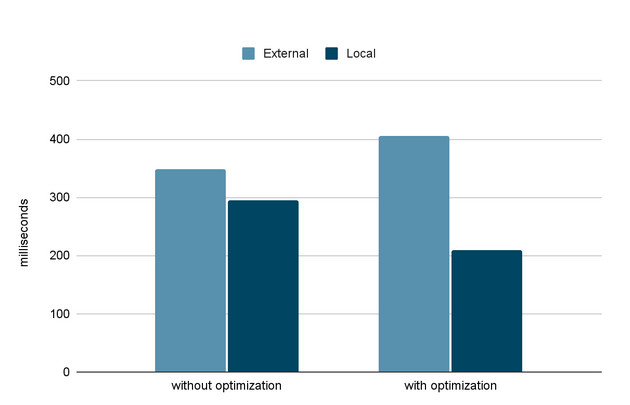
So, the main point here is that external calls become slower +18% because of the interstitial jump to the decorator but internal calls become much faster -30%. A good tradeoff, isn’t it?
Of course this is an artificial benchmark and the actual speedup will depend on how many indirect calls you do on your hot paths, but in the bug you can see that wasm-godot-baseline gets a 2% boost already.
Special thanks section
The original idea of this optimization belongs to Luke Wagner and this work is hard to even imagine without great support, help and reviews from Mozilla engineer Lars Hansen. Actually it was him who fixed the last bug to make this optimization alive. As always I want to say thanks to my Igalia colleague Andy Wingo for supporting and helping with many ideas for this optimization, check his amazing blog.
Also, I want to say thanks to all Mozilla engineers for the friendly environment and help with this stuff: Benjamin Bouver for fixing the bug in register allocator, Chris Fallin for updating Cranelift ABI, Julian Seward for pieces of advice with stack maps.
Conclusion and the future
Speedup is about 30% and this is great, but at the same time we pessimized truly external cases and use more memory for allocating decorators.
But this is all about internal stuff, what you as wasm user can take away from this post? Well, if you are going to use call_indirect then use as many private tables as you can and try to minimize the number of truly external calls. Also, don’t make your tables marked exported without real sharing it between modules because in this case the optimization can’t be applied.
BTW, this technique can be also applied to optimize null checks for call_indirect and new call_ref instruction from the typed function references proposal.
Hope this was an interesting reading, happy hacking and see you next time.